
Object Storage for Deep Learning Frameworks
2018년 DIDL 이라는 workshop에서 발표된 논문이고 저자들은 모두 이스라엘 Haifa의 IBM Research 소속이다.
데이터가 폭발적으로 많아지면서 Deep Learning (DL)으로 대표되는 Machine Learning(ML)이 매우 중요한 기술이 되었다. 특히, DL이 중요해진 계기 중 하나는 하드웨어 기반의 가속기 (GPU, FPGA, Tensor Processing Unit) 같은 것들 덕분이라고 한다. GPU를 활용한다고 가정했을 때, DL 을 위한 시스템 환경은 분산시스템 환경보다는 단일 시스템 (책상 위 PC 혹은 workstation)을 가정하고 있고, 훈련을 위한 데이터는 물리적으로 GPU와 같은 시스템에 존재한다고 가정한 것이다. 그래서 POSIX file system interface (Unix/Linux 에서 사용하는 File 인터페이스라고 생각하면 됨) 를 주요 데이터 접근 계층으로 가정하고 있다. (TensorFlow의 경우 Amazon S3 라는 Object Storage를 기본적으로 지원하기는 한다.)
이 모델은 어떻게 보면 scalable하지 않다. 비싼 GPU가 설치된 workstation pc 를 모든 엔지니어에게 나누어 주기도 그렇고, 그런다 한들 개별 PC에 설치할 수 있는 GPU 카드 갯수의 제약이 있고, 훈련에 필요한 데이터를 각 PC에 모두 복사하는 것은 현실적이지도 않고 비효율적이다. 그래서 요즘 사람들이 하는 일은 여러 개의 GPU 카드를 장착한 서버를 서버실에 (여러 개) 넣고, DDN 와 같은 비싼 파일 스토리지 장비를 사서 DGX-2가 POSIX file system interface를 통해 데이터를 읽고 쓸 수 있게 만든다.
이 논문은 Amazon S3 로 대표되는 Object Storage 를 DL 훈련을 위한 데이터 저장소로 활용하는 방안에 대해 살펴본다. 파일 시스템 대비 Object Storage의 장점은:
- Disaggregated Storage: S3 의 개념이 loosely-coupled storage service 이니, compute 를 수행하는 자원 (DL의 경우 GPU) 와 disaggregated 되어 있다 (고 말하는 것으로 추측된다)
- High scalability: (분산) file system 구현에 비해 Object Storage가 더 높은 확장성을 가진다… 고 믿어진다. 그 이유는 file system의 경우 metadata operation이 bottleneck이 되는 데 비해, object storage의 경우 그 부하가 덜 하다, 고 추측이 된다.
- Low cost
하지만 object storage는 이전에 비교한 고성능 파일시스템보다는 성능이 떨어지는 것으로 알려져 있다. 게다가 POSIX 파일시스템 인터페이스도 제공되지 않는다. 성능이 떨어지는 것이 왜 문제인가? 왜냐하면 GPU가 매우 비싸기 때문에, 최대한 사용율을 높이는 것이 효율적이기 때문이다. 논문의 Table 1. 은 다양한 DL workload에 대해 GPU 개수가 1개에서 8개까지로 늘어났을 때, 얼마나 높은 데이터 대역폭(MB/s)이 요구되는지 기록해 두었다.
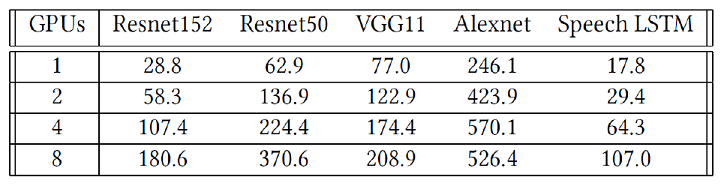
예를 들어 Alexnet의 경우 GPU 8개를 사용하면 526 MB/s 이 필요하다고 하는데, 이는 매우 높은 수치이다. 따라서 Object Storage를 DL framework에서 사용하기 위해서는, 1) 고성능이 필요하며, 2) POSIX-compilant file system이 필요하다.
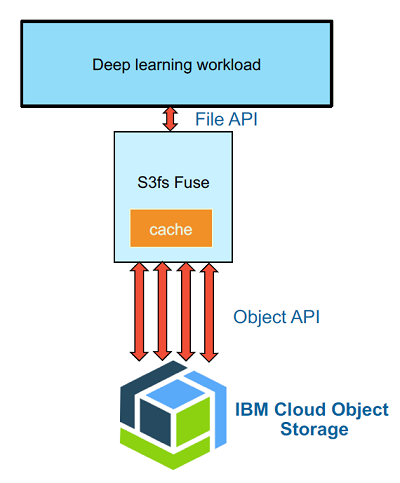
이 논문에서는 Figure 1. 과 같은 구조를 제시한다. s3fs 라는 FUSE 기반의 소프트웨어를 사용하여 Object Storage 에 저장된 데이터를 Deep Learning Framework 들은 마치 (로컬) 파일시스템을 활용하는 것 처럼 느끼게 할 수 있다. 그렇다면 고성능은 어떻게 제공할까?
- DL 에서 training data를 접근하는 것은 (대부분) 읽기 동작 이다. 따라서 Cache 가 효과적일 수 있다. 이 논문에서는 s3fs 에 in-memory cache 기능을 구현하였다고 한다.
- data chunk 뿐만 아니라 meta data도 cache 하였다.
- DL framework 들은 여러 번의 epoch 를 통해 training 하므로, 데이터가 캐시 안에 들어있기만 하다면 캐싱 효과가 매우 크다
- Object Storage는 하나의 request에 대해 높은 throughput을 제공하기 보다는 multi-user, multi-tenant 환경에 맞게 설계되어 있다. 그래서 하나의 read request 를 여러개의 (S3) requests 를 동시에 보내는 것으로 변환했다.
- client 가 원하는 만큼만 데이터를 읽는 것이 아니라, 일정 크기의 ‘chunk’를 항상 읽게 해서 prefetching 하는 효과를 내게 했다. 실험 결과 자신들의 환경에서는 52 MB가 최적의 크기였다고 한다.
작은 파일이 많이 있는 것은 오버헤드가 크니, 여러개의 작은 파일을 TensorFlow에서는 TFRecord, pyTorch에서는 HDF5 와 같은 큰 단일 파일로 합치는 것을 권장한다. 이렇게 한다면 Object Storage에도 도움이 된다.